
Warum Fließtexte von gestern sind
Die Entwicklung von Medizinprodukten bewegt sich heute in einem Spannungsfeld aus steigendem Innovationsdruck und wachsenden regulatorischen Anforderungen. Produkte werden komplexer, oft mit einem hohen Softwareanteil, und müssen gleichzeitig schneller zur Marktreife gebracht werden. Die Normen EN 14971, EN 62304 und EN 62366 setzen dabei klare Maßstäbe – und verlangen lückenlose Nachweise über Sicherheit, Funktionalität und Gebrauchstauglichkeit.
Viele Unternehmen versuchen, diesen Balanceakt mit traditionellen Mitteln zu meistern: Word-Dokumente, Excel-Tabellen, manuelle Review-Prozesse. Was dabei entsteht, sind schwerfällige Dokumentationsberge, inkonsistente Datenstände und Prozesse, die den Anforderungen moderner Produkt-entwicklung nicht mehr gewachsen sind.
Hier liegt das Problem – und die Chance zugleich.
Ein integriertes Datenmodell bricht mit diesen alten Gewohnheiten. Es ersetzt unstrukturierte Fließtexte durch klar definierte Datenobjekte, die in logischen Beziehungen zueinanderstehen. Anforderungen, Risiken, Testfälle – alles ist verknüpft, überprüfbar und automatisierbar. Anstelle fragmentierter Informationen entsteht ein transparenter, steuerbarer Entwicklungsprozess, der nicht nur die Normen erfüllt, sondern Ihnen auch den Freiraum gibt, sich auf das Wesentliche zu konzentrieren: ein sicheres, innovatives und marktreifes Produkt.
Dieser Beitrag zeigt, wie Sie mit Hilfe intelligenter Datenmodelle:
- die Komplexität der Produktentwicklung beherrschen,
- Fehlerquellen frühzeitig eliminieren,
- Ressourcen effizient einsetzen und
- normgerechte Nachweise nicht nur erfüllen, sondern elegant integrieren.
Anhand konkreter Modell-Beispiele erfahren Sie, wie Datenmodelle zum Schlüssel für mehr Qualität, Geschwindigkeit und Sicherheit werden. Entwickelt für all jene, die im MedTech-Bereich nicht nur verwalten, sondern gestalten wollen: Entwickler, Usability- und Risikomanager, Qualitätsverantwortliche – und Entscheider, die den Unterschied zwischen
Mittelmaß und Marktführerschaft kennen.
Fließtexte: Der blinde Fleck im Entwicklungsprozess
In vielen Entwicklungsabteilungen sind Word-Dokumente und Excel-Tabellen immer noch die Grundlage des Anforderungs- und Risikomanagements. Jahrzehntelang bewährt, doch in einer Welt, in der Produkte immer komplexer und Normen immer strikter werden, sind diese Werkzeuge längst überfordert.
Die typischen Schwächen von Fließtext-Dokumentationen:
1. Redundanzen und Inkonsistenzen:
- Informationen werden oft mehrfach erfasst, oder identische Aussagen variieren verbal.
- Redundante Informationen müssen an vielen Stellen manuell geändert werden.
- Unterschiedliche Dokument-Versionen führen zu Missverständnissen.
2. Mangelnde Verknüpfbarkeit:
- Anforderungen, Risiken und Testfälle existieren getrennt, oft in verschiedenen Dokumenten bzw. Dateien.
- Keine automatische Traceability – die Rückverfolgbarkeit erfolgt meist in aufwendigen und fehleranfälligen Excel-Tabellen.
- Zusammenhänge werden nur durch Interpretation der Beteiligten hergestellt.
3. Fehleranfälligkeit und Aufwand:
- Manuelle Konsistenzprüfungen der Informationen sind fehleranfällig und zeitintensiv.
- Gate Reviews geraten zur Mammutaufgabe, deren Ergebnisse oft unvollständig bleiben.
- Audits durch Benannte Stellen decken Schwächen gnadenlos auf.
4. Kein Echtzeit-Überblick:
- Statusänderungen sind nicht sofort sichtbar.
- Fortschritte in Teilbereichen bleiben unsichtbar.
- Frühzeitiges Erkennen von Risiken wird erschwert, da Warnsignale oder Zusammenhänge oft zu spät erkannt werden.
Fließtexte sind sehr flexibel – und genau das ist ihr Problem.
Fließtexte erlauben Interpretationsspielräume, die bei sicherheitskritischen Produkten zum Verhängnis werden können. Wenn Anforderungen nicht eindeutig sind, Tests nicht sauber dokumentiert oder Risiken nicht transparent bewertet, leidet nicht nur die Qualität – es entstehen Kosten, Verzögerungen und rechtliche Risiken.
Warum Datenmodelle hier klar überlegen sind:
- Sie erzwingen Klarheit: Nur strukturierte Daten werden akzeptiert.
- Sie verhindern Redundanz: Jedes Artefakt existiert genau einmal – Beziehungen statt Kopien.
- Sie ermöglichen Automatisierung: Prüfungen laufen kontinuierlich, nicht nur punktuell.
- Sie geben Kontrolle: Jede Änderung wird dokumentiert, jede Beziehung sichtbar.
Fließtexte mögen für die ersten Konzepte brauchbar sein – aber wer komplexe Medizinprodukte entwickeln will, braucht Systematik. Und die beginnt beim Abschied von Word und Excel als Hauptwerkzeuge.
Grundlagen effizienter Datenmodelle
Was ist ein Datenmodell?
Ein Datenmodell beschreibt die strukturierte Abbildung aller relevanten Informationen eines Produkts in Form von verknüpften Objekten (Artefakten bzw. Items) mit klar definierten Attributen. Anders als in Dokumenten, wo Informationen oft implizit enthalten sind, wird im Datenmodell jede Information explizit und maschinell auswertbar erfasst.
Aufbau eines Datenmodells
Datenobjekte
Ein Datenmodell besteht hauptsächlich aus Datenobjekten. Dies können z.B. Anforderungen, Testfälle, Risiken oder Defekte sein. Jedes dieser Objekte hat eine eindeutige ID und Attribute, die das Objekt beschreiben. Diese Attribute können obligatorisch oder optional sein.
Attribute
Die folgende Abbildung zeigt mögliche Attribute, mit denen eine Anforderung näher definiert werden kann. So ist es z.B. sinnvoll, die Voraussetzung für eine Anforderung von der eigentlichen Anforderung zu trennen. Dadurch kann sichergestellt werden, dass Anforderungen genauer definiert werden. Dies ist wichtig, da z.B. eine „wenn-dann“-Bedingung und eine „genau-dann“-Bedingung auf den ersten Blick ähnlich klingen, sich aber hinsichtlich des erforderlichen Testdesigns deutlich unterscheiden. Es ist auch sehr hilfreich, die Frage nach dem „Warum?“ in einer Anforderung zu klären, da es für viele Designentscheidungen durchaus unterschiedliche Intentionen geben kann und diese Intentionen wiederum einen entscheidenden Einfluss auf die Kritikalität in der Risikobetrachtung haben, wenn man analysieren muss, was passiert, wenn ein Designelement seinen Zweck gemäß Spezifikation erfüllt oder nicht.
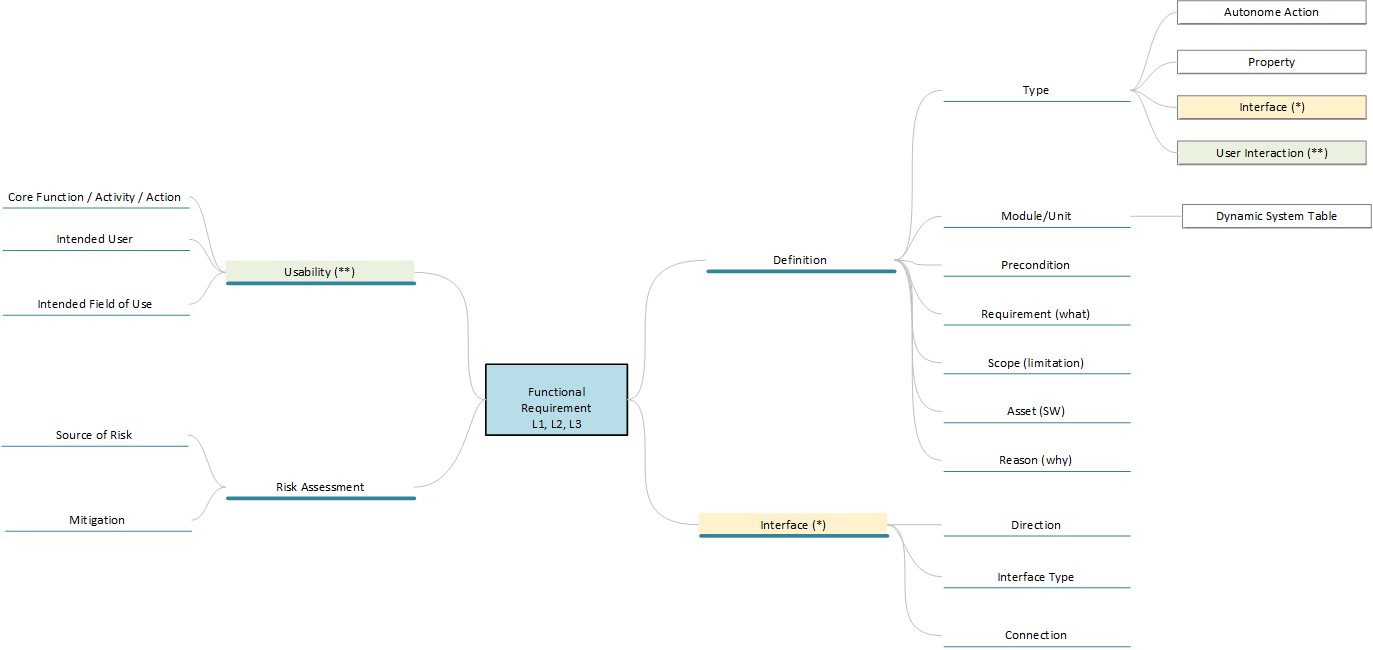
Auch bei den Attributen sollte Freitext oder Fließtext möglichst vermieden werden. Dies reduziert Fehler bei der Interpretation der Daten und verbessert die Möglichkeiten der maschinellen Verarbeitung. Verwenden Sie auch keine Checkboxen. Diese sind zwar sehr einfach zu handhaben, aber im Zweifelsfall kann nicht festgestellt werden, ob eine Checkbox leer ist, weil der Autor es so wollte oder weil er es nicht bearbeitet hat.
Workflows
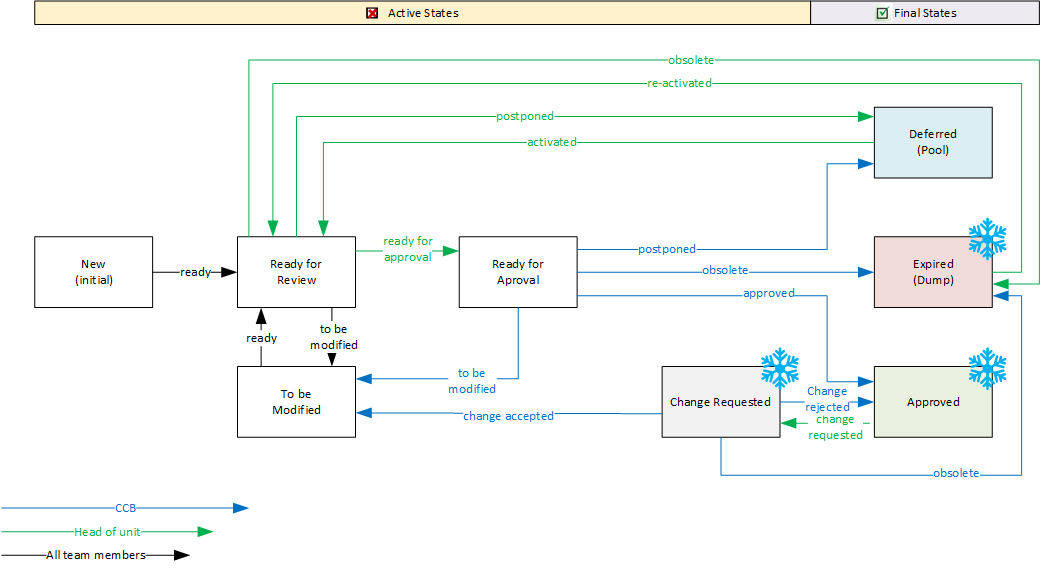
Eigentlich ist ein Workflow auch ein Statusattribut, nur dass dessen Werte den Bearbeitungsstand des Datenobjekts wiedergeben und dessen Werte nur entlang bestimmter Pfade durchlaufen werden können.
Die folgende Abbildung zeigt einen möglichen Workflow für ein Requirement, wobei die aktive Phase die möglichen Bearbeitungs- und Prüfschritte darstellt und ein Requirement abschließend im Status „Approved“ oder auch als „Zurückgestellt“ für einen späteren Zyklus markiert werden kann. Zu beachten ist auch, dass ein Requirement „Expired“ werden kann, da ein Objekt für eine vollständige Historie nicht aus dem Modell entfernt wird. Wenn Prozessübergänge nur autorisierten Personengruppen vorbehalten sind und diese ggf. mit systematischen Datenprüfungen verbunden sind, hat man ein effektives Werk-zeug für das Projektmanagement in der Hand.
Relationen
Relationen beschreiben die Beziehungen zwischen zwei oder mehreren Datenobjekten. Beispielsweise prüft ein Test Case als „Definition of Done“ die Umsetzung einer Anforderung oder mehrere risikomindernde Maßnahmen (Mitigations) beziehen sich auf das zu mindernde Risiko. Es ist auch möglich, Datenobjekte gleichen Typs in Beziehung zu setzen. So kann z.B. eine Anforderung mit einer anderen Anforderung in Beziehung stehen, weil sie sich im Design gegenseitig bedingen oder eine Schnittstelle zwischen Designelementen beschreiben.
Da in einem Datenmodell mit sehr vielen Relationen gearbeitet wird, ist es wichtig, auch diese Typen eindeutig zu benennen, da sie oft die Grundlage für Abfragen und Analysen bilden. Hierfür gibt es verschiedene Möglichkeiten. Bewährt hat sich die Eltern-Kind-Beziehung, für die folgende Grundregeln gelten:
- Ein Kind-Objekt referenziert immer auf ein Elternobjekt, d.h. die Flussrichtung der Relation zeigt immer vom Kind zum Elternobjekt
- Die Benennung der Relation erfolgt immer in Flussrichtung „[Kind] steht in Beziehung zu [Eltern]“.
Zum Beispiel kann eine Relation zwischen einem Test Case und einem Requirement wie folgt benannt werden: „[Test] prüft [Requirement]“ (siehe nachfolgende Abbildung).

Vorteile in der Praxis
Wie aus der Beschreibung hervorgeht, bietet ein solches Datenmodell in der Praxis viele Vorteile. Die drei offensichtlichsten sind:
- Automatisierte Prüfungen
Daten können auf Basis von automatischen Abfragen gefunden werden, z.B. „Zeige alle Requirements vom Typ „Interface“ in Baugruppe „A““ oder „Zeige alle Requirements, die ohne einen Test Case sind“. Die Möglichkeiten skalieren mit der Granularität des Datenmodells und können auch automatisiert zu ganzen Audit Trails zusammengefasst werden. - Flexibilität & Skalierbarkeit
Modelle können iterativ erweitert werden, indem neue Datentypen hinzugefügt werden oder bestehende Datentypen um neue Attribute erweitert werden. Im Gegensatz zu Fließtexten ist das Hinzufügen von neuen Attributen ohne großen Aufwand möglich, da keine syntaktische Morphologie berücksichtigt werden muss. - Standardisierung
Die Attribute in den Datenobjekten entsprechen den zu bearbeitenden Formularen. Sie sind wie eine Checkliste und stellen sicher, dass alle notwendigen Informationen eines Designartefakts er-fasst werden. Sie sorgen für eine einheitliche Vorgehensweise und einen einheitlichen Stil in der Entwicklungsdokumentation. Dies gilt nicht nur für die jeweiligen Projekte sondern auch projektübergreifend – eine grundlegende Vorbereitung und Voraussetzung für die Einführung von Produktplattformen, bei denen ein Portfolio von Modulen zu verschiedenen Produkten rekombiniert wird.
Verbesserte Tiefenschärfe: Traceability als systemisches Steuerungselement
Traceability – die lückenlose Rückverfolgbarkeit aller möglichen Kausalzusammenhänge einer Produktentwicklung – ist in der Medizintechnik nicht nur ein regulatorisches Muss, sondern auch ein entscheidender Qualitätsfaktor. Normen wie EN 14971, EN 62304 und EN 62366 fordern sie – doch ein intelligentes Datenmodell hebt Traceability auf eine neue Ebene: weg vom Aufwand, hin zum strategischen Vorteil.
In Konstruktionsmodellen können die Beziehungen zwischen den Konstruktionsartefakten sehr vielfältig und komplex sein. Das ist insofern kein Problem, als solche Beziehungen sehr gut von Maschinen – Datenbanken – verwaltet und überwacht werden können.
Viele Konstruktionsmodelle betrachten das Produkt aus verschiedenen Ebenen oder Perspektiven. EN 62304 definiert drei verschiedene Ebenen. Obwohl sich diese Norm speziell auf die Entwicklung von Software für Medizinprodukte bezieht, ist das Konzept in vielen Modellansätzen verbreitet und kann für jede Art der Produktentwicklung verallgemeinert werden.
- Die Stakeholder-Ebene ist die erste Ebene des Design-Modells. Von hier aus hat man eine monolithische Sicht auf das Produkt und konzentriert sich auf die Eigenschaften oder den Nutzen, den das Produkt haben muss, um die Bedürfnisse der verschiedenen Stakeholder zu erfüllen, die mit dem Produkt.
- Die System-Ebene ist der Stakeholder-Ebene nachgelagert. Hier wird das technische Konzept entworfen, mit dessen Hilfe die Anforderungen der Stakeholder erfüllt werden sollen. Basierend auf den gewählten Technologien und den zu erfüllenden Aufgaben werden Module definiert, die bestimmte Teilaufgaben erfüllen müssen und somit untereinander und mit ihrer Umwelt in Wechselwirkung stehen.
- Der Design-Output ist die dritte Ebene. Hier wird für jedes Systemmodul die konkrete technische Umsetzung definiert. Es ist also die technische Blaupause, nach der das Produkt letztendlich gebaut wird.
Ausgehend von diesen Designebenen werden zwei Richtungen der Traceability betrachtet – die vertikale Traceability, d.h. die Zusammenhänge zwischen den Designebenen und die horizontale Traceability, die Abhängigkeiten innerhalb einer Designebene.
Vertikale Traceability
Die vertikale Traceability zeigt also, wie jede Anforderung von einer Abstraktionsebene zur nächsten weitergegeben wird – von den Wünschen der Stakeholder über die funktionale Systemarchitektur bis hin zur konkreten Umsetzung. D.h. es muss sichergestellt werden, dass jede Anforderung einer übergeordneten Ebene durch mindestens eine Anforderung einer untergeordneten Ebene abgedeckt wird. Dabei kann es durchaus vorkommen, dass es in der untergeordneten Ebene Anforderungen gibt, die keinen offensichtlichen Bezug zur übergeordneten Ebene haben, da sie sich aus der Notwendigkeit der neuen Entwurfsperspektive ergeben.
Wenn z.B. ein Notarzt als einer der Stakeholder fordert, dass er eine bestimmte Diagnose völlig autark von äußeren Bedingungen durchführen kann und diese Diagnose eine Technologie erfordert, die elektrische Energie benötigt, so muss der Systemarchitekt ein Modul definieren, das die benötigte Energie zur Verfügung stellt. Dabei kann er entscheiden, ob die benötigte Energie bei Bedarf erzeugt oder aus einem Energiespeicher bereitgestellt wird. Entscheidet er sich für einen Energiespeicher, so muss der Produkt-entwickler auf Ebene 3 die geeigneten Speichermedien, Gleichrichter und Ladegeräte mit allen Schaltplänen und Spezifikationen entwerfen, so dass die Energiequelle des Gerätes den geforderten Leistungsanforderungen entspricht. Das bedeutet, dass die jeweiligen Anforderungen einer Ebene mit den Anforderungen der benachbarten Ebenen verknüpft sind. Durch Datenmodelle wird diese Kette transparent, so dass Änderungen einer Anforderung auf einer Ebene automatisch zu Überprüfungen der damit verbundenen Anforderungen führen.
Horizontale Traceability
Die horizontale Traceability stellt sicher, dass alles innerhalb einer Designschicht zusammenpasst. Eine der grundlegendsten Beziehungen in einer Designspezifikation ist die bereits erwähnte Beziehung zwischen Anforderung und Test, die „Definition of Done“ genannt wird. Diese Beziehung stellt sicher, dass die Implementierung jeder Anforderung verifiziert oder validiert wird. Umgekehrt können Anforderungen in Root Cause Analysen leichter identifiziert werden, wenn Tests fehlschlagen oder Fehler in einem Produkt gemeldet werden. Manchmal führen solche Fehler auch zur Entdeckung von Lücken in der Designspezifikation, da die Fehler auf Anforderungen zurückgeführt werden können, die für das Produkt nicht klar definiert wurden.
Mit abnehmender Flughöhe in den Design-Ebenen nimmt die Komplexität zwischen den Datenobjekten zu. Dies gilt sowohl für den Informationsgehalt einzelner Design-Artefakte als auch für deren Beziehungen untereinander. Es kann daher nur nochmals betont werden, dass gut strukturierte Daten mit eindeutigen Attributen und klar unterscheidbaren Linktypen eine wesentliche Grundvoraussetzung sind, um diese Komplexität zu beherrschen.
Auch der Zusammenhang zwischen Requirements, Risiken und Mitigations lässt sich abbilden und über-wachen. Auf dieses Konzept wird nachfolgend noch genauer eingegangen.
Um beim Beispiel unseres Diagnosegeräts zu bleiben, kann eine weitere Forderung sein, dass das Gerät eine hohe Ausfallsicherheit haben muss. Dem Risiko, dass das Energiemodul ausfällt, begegnet der Systemarchitekt mit zwei Mitigations – einer redundanten Auslegung der Stromversorgung und einer Vor-richtung zur Notfallumschaltung. Daraus ergeben sich drei Prüffälle, der Implementierung der zusätzlichen Vorrichtungen und ihrer Wirksamkeit im Fehlerfall.
Jede dieser Komponenten ist in der Systemebene miteinander verknüpft. Eine Änderung in der Spezifikation der Stromquelle (z.B. eine höhere Lastaufnahme) wirken automatisch auf das Risiko, das Mitigationsdesign und den Testplan.
Meta-Ebene der Traceability – Organisatorische Auswirkungen
Traceability ist kein bürokratischer Akt – sie ist der Kompass, der durch die regulatorischen Anforderungen führt. Ein Datenmodell sorgt dafür, dass Sie nie die Orientierung verlieren. Es ist nicht nur ein Projektinstrument, sondern:
- Audit-Werkzeug: Jederzeit vollständige Informationsstände zu Prozessen und konsistente und normen-konforme Dokumente.
- Qualitätssteuerung: Fehlerquellen werden durch logische Prüfungen minimiert.
- Wissensmanagement: Wiederverwendbare Module und Anforderungen für zukünftige Projekte.
- Compliance-Garantie: Direkte Verknüpfung mit Norm- und Gesetzesanforderungen.
Das Datenmodell im Einsatz
Risiko Management – Integration und Tiefe
Eine zentrale Herausforderung bei der Entwicklung von Medizinprodukten ist das Risikomanagement nach EN 14971. Es muss sichergestellt werden, dass Risiken systematisch erkannt und entsprechende Designänderungen oder risikominimierende Maßnahmen sowie Benutzerinformationen umgesetzt werden.
EN 14971 Integration
Systematische Ermittlung von Risiken
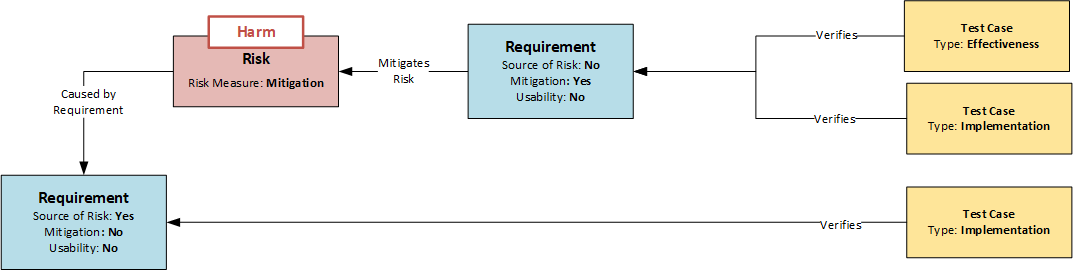
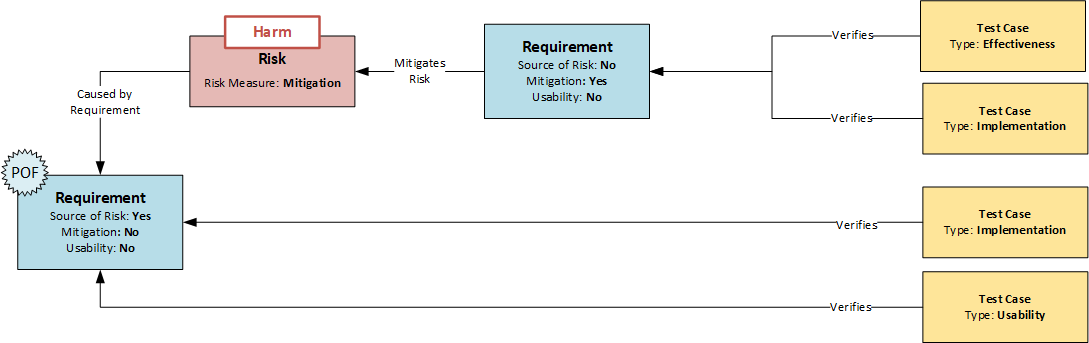
Der erste entscheidende Punkt ist bereits die systematische Ermittlung der Risiken. Eine in der Praxis häufig angewandte Methode ist die Risikobewertung des Gerätes anhand eines Themenkatalogs. Dabei wird beurteilt, ob Risiken einer bestimmten Kategorie bei dem betreffenden Produkt zu erwarten sind. Wenn ja, werden diese gesucht (Top-Down-Analyse). Die Methode hat System, garantiert aber nicht die Vollständigkeit der Ergebnisse. Eine wesentlich tiefer gehende Analyse ist möglich, wenn jede Anforderung als potentielle Quelle eines Risikos untersucht wird. Diese Untersuchung kann durch ein entsprechendes Attribut im Datenobjekt Requirement gesteuert werden. Wenn sich eine Anforderung als Quelle eines Risikos herausstellt, wird dies kurz beschrieben und durch Setzen des Attributs „Source of Risk“ gekennzeichnet (siehe Abbildung: Modell der Abhängigkeiten von Requirements, Risiken und Test Cases). Dies wäre nun die Bottom-Up-Analyse, bei der alle Anforderungen des Produkts systematisch untersucht werden.
Den identifizierten Risiken muss nun mindestens ein Datenobjekt vom Typ Risiko zugeordnet werden, welches wiederum das Risiko anhand einer Liste vorgegebener Attribute näher beschreibt. Verwendet man für die Attribute ebenfalls die oben genannten Risikokategorien, können Bottom-Up- und Top-Down-Analyse miteinander kombiniert werden, was die Fehleranfälligkeit der Methode, ähnlich der Zwei-Konten-Methode in der Buchhaltung, reduziert. Dabei können einer Anforderung mehrere Risiken oder mehreren Anforderungen das gleiche Risiko zugeordnet werden.
Im Gegensatz zu den Tabellen sind Risiken jetzt keine toten Listen mehr, sondern vernetzte Knotenpunkte im System, die auf Änderungen sensibel reagieren.
Mitigations sind Requirements
Entscheidet man sich dafür, das Risiko zu minimieren, werden Mitigations (risikomindernde Maßnahmen) definiert, mit deren Hilfe die Eintrittswahrscheinlichkeit des Risikos verringert wird. Dies sind Anforderungen an das Design – also Requirements. Um sie im Risikomanagement als besondere Anforderungen zu kennzeichnen, erhalten sie das Attribut „Mitigation“ und verweisen auf das Risiko oder die Risiken, die sie minimieren sollen (siehe Abbildung: Modell der Abhängigkeiten von Requirements, Risiken und Test Cases). So kann auch bei späteren Konstruktionsänderungen der Bezug zu den Risiken erkannt werden.
Die EN 14971 fordert, dass die Mitigations selbst wiederum auf mögliche Risiken überprüft werden müssen. Da in diesem Modell ausnahmslos alle Anforderungen geprüft werden, ist diese Forderung erfüllt.
Implementierung und Effectiveness
Ein weiterer wichtiger Aspekt ist die Überprüfung der Wirksamkeit. Wie bereits erwähnt, ist jeder Anforderung mindestens ein Testfall zugeordnet, mit dem die Umsetzung der Anforderung überprüft wird. Ist eine Anforderung jedoch mit dem Attribut „Mitigation“ gekennzeichnet (siehe Abbildung), so muss neben der klassischen Prüfung der Umsetzung (Implementation) gemäß EN 14971 auch die Wirksamkeit (Effectiveness) der Maßnahme geprüft werden. Es werden also zwei Prüfungen benötigt:
- Umsetzungsprüfung: Wurde die Mitigation technisch korrekt umgesetzt?
- Prüfung der Wirksamkeit: Reduziert die Mitigation das Risiko tatsächlich auf das akzeptable Maß?
Dementsprechend gibt es auch verschiedene Typen des Datenobjekts Test Case. Die Unterscheidung kann im einfachsten Fall wiederum über ein Attribut erfolgen, wie die folgende Abbildung zeigt. Mit Hilfe der jeweiligen Attribute „Implementation“ und „Effectiveness“ kann die korrekte Testabdeckung durch eine entsprechende Abfrage von Relationen und Attributen plausibel überwacht werden: „Zeige alle An-forderungen mit dem Attribut „Mitigation“, die nicht von mindestens einem Testfall mit dem Attribut „Implementation“ und mindestens einem Testfall mit dem Attribut „Effectiveness“ abgedeckt werden.
Abgeschlossenheit einer Designebene
Mitigations führen letztendlich immer zu einem oder mehreren Design Outputs. Um jedoch auf den Designstufen (1) und (2) keine „offenen Enden“ hinsichtlich der notwendigen Anforderungen zu hinterlassen, ist es ratsam, die Mitigation der Risiken auf der Designstufe durchzuführen, auf der sie identifiziert wurden. Dies ist auch insofern von Vorteil, als die erforderlichen Maßnahmen aus der gleichen Entwurfsperspektive definiert werden, aus der das Problem erkannt wurde. Es ist also kein gedanklicher Sprung erforderlich. Zum anderen besteht die Möglichkeit, bei den Gate Reviews beim Verlassen einer Designebene bereits eine in sich geschlossene Prüfung durchzuführen – ein Risiko soll reduziert werden und dafür ist mindestens eine Maßnahme definiert. Die bereits bei der vertikalen Traceability erwähnte Forderung nach Design Coverage, d.h. jedes Requirement einer höheren Ebene soll durch mindestens ein Requirement der nachfolgenden Ebene abgedeckt sein, stellt sicher, dass alle Maßnahmen bis zum Design Output durchgereicht werden. So bleiben einmal identifizierte Anforderungen bis zum Ende auf dem Radar.
Zusammenfassung – Modell Risiko Management
Für das Risiko Management mit Hilfe des Datenmodells, welches in der obigen Grafik dargestellt ist, lassen sich folgende Aussagen zusammenfassen:
- Requirements werden im Datenobjekt „Requirement“ beschrieben
- Jedes Requirement wird systematisch dahingehend untersucht, ob aus dem Design bei korrekter oder fehlerhafter Funktion ein Risiko erwachsen kann, wenn dem so ist, erhält dieses das Attribut „Source of Risk“.
- Risiken werden im Datenobjekt Risiko beschrieben und verweisen auf die Quelle(n) (Requirements) aus denen sie hervorgehen.
- Wird ein Risiko minimiert so geschieht das durch eine Mitigation.
- Mitigations sind Requirements, die hinsichtlich Ihrer Prüfung allen Anforderungen der Requirements unterliegen. Sie erhalten das Attribut „Mitigation“.
- Requirements mit dem Attribut „Mitigation“ werden nicht nur in Bezug auf ihre Implementierung sondern auch auf die Effektivität der Risikominimierung getestet.
5.1.2 Tiefe der Analyse
Die Integration der Risiken als Knoten in das große Datennetz zeigt, aus welchen Anforderungen sie resultieren und durch welche Maßnahmen sie zu beherrschen sind. Jede Designänderung kann somit risikosensitiv durchgeführt werden. Es wird auch sehr schnell deutlich, wie groß der Einfluss eines bestimmten Risikos ist und wie viele Teilsysteme davon betroffen sein können.
Man kann die Information über die Risikoverbindungen auch dazu nutzen, seine Entwicklungsressourcen zu priorisieren, um Sicherungen an den richtigen Stellen mit der höchsten Wirksamkeit zu implementieren.
Wenn man nun noch die Schäden mit ihren Schweregraden von den Risiken in eigenständige Datenobjekte trennt – was wiederum den Aufwand reduziert und die Risikobewertung weiter standardisiert – ist man auch in der Lage zu sehen, welche Risiken gleiche oder ähnliche Schäden verursachen, was viele Vor-teile bei der Bewertung des Gesamtrisikos bringt.
Usability Engineering: Prozessintegrierte Sicherheit
Usability Engineering: Prozessintegrierte Sicherheit
Von Handlungen zu Requirements
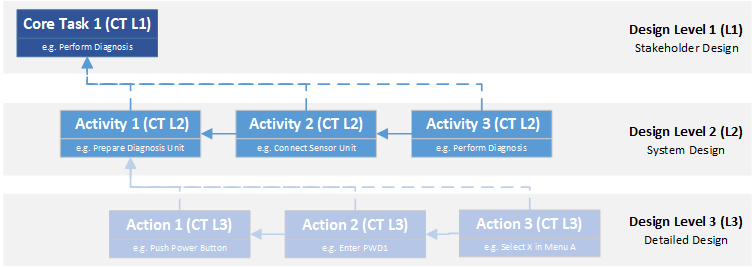
Der Umgang mit einem Medizinprodukt lässt sich ebenfalls in die Perspektive der Designebenen Integrieren. Eine Handlung ist die Interaktion mit dem Produkt als Ganzes – der Arzt möchte ein EKG ableiten. Dazu führt er Interaktionen mit einzelnen funktionalen Baugruppen durch – er legt Elektroden an und arbeitet mit dem User Interface des Messverstärkers. Um dies letztlich tun zu können, benutzt er Knöpfe, bedient Schalter oder liest Skalen ab. D.h. alle diese Handlungen, Tätigkeiten und Interaktionen stehen auf den entsprechenden Ebenen mit Requirements in Relation, die diese User Interaktionen definieren.
Identifikation risikokritischer Interaktionen
Die EN 62366 führt das Konzept der „Primary Operating Functions“ (POF) ein. Dies sind Funktionen, die in direktem Zusammenhang mit der Sicherheit des Medizinproduktes stehen. Die FDA verwendet in ihrer Richtlinie: „Applying Human Factors and Usability Engineering to Medical Devices“ (FDA Guidance 2016) den Begriff „Core Function“, der ähnlich aufgebaut ist. Die Identifikation dieser Funktionen ist ein wesentlicher Schritt im Usability-Engineering-Prozess und kann ebenfalls in das hier vorgestellte Datenmodell integriert werden.
Dazu werden alle Requirements, die sich auf Handlungen beziehen und damit die systemseitige User Interaktion definieren, mit dem Attribut „Usability“ versehen. Ist ein Requirement mit dem Attribut „Usability“ gleichzeitig auch die Quelle eines Risikos (Attribut „Source of Risk“), so sind sicherheitsrelevante Funktionen bei der Bedienung des Gerätes identifiziert und können anhand der normativen Anforderungen weiter bearbeitet werden. Ähnlich wie bereits bei der Mitigation beschrieben, ergeben sich weitere Möglichkeiten der Überwachung. So müssen z.B. derartige Anforderungen nicht nur hinsichtlich ihrer Implementierung getestet werden, sondern erfordern zusätzlich Usability-Tests, die auf System- und Design-Output-Ebene als formative Tests und auf Stakeholder-Ebene als summative Tests durchgeführt werden müssen.
Informationen für das Usability File
Die gesamte Entwicklung von Medizintechnik ist risikozentriert, so dass auch die EN 62366 und die EN 14971 eng miteinander verknüpft sind. Usability-Risiken können daher in einem einheitlichen Risiko Management Prozess erfasst werden, ohne von der oben dargestellten Vorgehensweise abzuweichen. Um Usability-Risiken dann in die Usability Akte zu überführen, werden alle Risiken gesammelt, deren „Source of Risk“ das Attribut „Usability“ aufweist. Usability-Risiken stellen in diesem Modell nur eine Teilmenge der Gesamtrisiken dar.
Zusammenfassung – Modell Usability Engineering
Zum ausführen des Usability-Engineerings mit Hilfe des integrierten Datenmodells (siehe nachfolgende Abbildung), lassen sich folgende Aussagen zusammenfassen:
- Steht ein Requirement unmittelbar im Zusammenhang mit einer User Interaktion so erhält es das Attribut „Source of Risk“
- Sind Requirements mit dem Attribut „Usability“ gleichzeitig Quelle eines Risikos – erhalten also das Attribut „Source of Risk“, so weisen diese auf eine sicherheitskritische Interaktion hin (Primary Operating Function)
- Requirements mit den Attributen „Usability“ und „Source of Risk“ sollten nicht nur in Bezug auf ihre Implementierung sondern auch hinsichtlich der Usability (summativ/formativ) getestet wer-den. Alle Risiken, deren „Source of Risk“ das Attribut „Usability“ trägt, werden als Risiken in die Usability-Akte übertragen.
Tiefe der Analyse
Die vorgestellte Vorgehensweise verfügt über eine hochgradige Systematik, mit der Risiken in der Gebrauchstauglichkeit mit hoher Sicherheit identifiziert werden können. Wenn in den Requirements vom Typ „Usability“ auch die Zielgruppen der Anwender erfasst werden, für die dieses funktionale Design geplant wurde, z.B. Ärzte, Pflegepersonal, Patient oder Servicetechniker, so können diese Informationen automatisch in das Test-Design übernommen werden. Basierend auf diesen Informationen lassen sich gezielt Testläufe für summative Usability-Tests planen, die für bestimmte Zielgruppen vorgesehen sind. Gleiches gilt für die Relationen aus Interaktion und Requirement. Hier lassen sich aus dem Datenmodell gezielt Testszenarien für die Usability Tests ableiten.
Durch die Verlinkung funktioniert aber auch die Rückrichtung. Jeder Fehler im Usability-Test fließt direkt zurück in die Risikoakte und kann hier ggf. eine Neubewertung der Risiken triggern.
Werkzeuge und Umsetzung: Von der Theorie zur operativen Exzellenz
Warum klassische Tools scheitern – und spezialisierte Systeme den Unterschied machen
Die Anforderungen an moderne Entwicklungsprozesse in der Medizintechnik sind hoch – und steigen weiter. Dokumentationspflichten, Nachweisführung, Änderungsmanagement, Integration von Normen: All das lässt sich mit traditionellen Office-Tools nicht mehr zuverlässig bewältigen.
Kernprobleme klassischer Tools (Word/Excel):
- Keine strukturierte Datenhaltung
Informationen haben keine Vorgaben bezüglich ihrer Form oder Ihres Inhalts – und wenn, sind sie stark von der Disziplin und den Fähigkeiten der Teams abhängig. Mit anderen Worten, es fehlt der rote Faden, an dem man sich bei seiner Aufgabe entlang hangeln kann. Die Beziehungen der Artefakte sind nicht systematisch erfassbar. Sie werden meist in den Kontext von Überschriften eingebettet – aber was, wenn man die Perspektive ändern möchte? - Manuelle Pflege
Dokumentenzentrierte Informationen in starren Gliederungen erzwingen oft redundante Inhalte. Die erhöht den Aufwand bei ihrer Gestehung und potenziert sich im Falle notwendiger Änderungen. Haben Sie schon einmal überlegt, in wieviel Dokumenten Sie auf den Intended Use Ihres Gerätes verweisen? Auch ist die Logik, anhand der Sie Ihre Daten pflegen können äußerst begrenzt und es hängt wiederum viel von den Fähigkeiten und der Disziplin Ihrer Prüfer ab. - Begrenzte Skalierbarkeit
Mit der Komplexität Ihrer Produkte oder der Vielfalt Ihrer Anwendungsmöglichkeiten wächst die Anzahl der Artefakte. 1.000+ Requirements sind keine Seltenheit, dazu die Tests und die Risiken und es wird unübersichtlich. Ist ihnen bewusst, das Traceability-Matrizen exponentiell, und nicht linear wachsen? Noch komplexer wird es, wenn Sie Designmodule in einer Produktplattform rekombinieren. Aber gerade Produktplattformen haben ein hohes Maß an Skaleneffekten und bieten ideale Möglichkeiten zur Diversifikation Ihres Produktportfolios.
Anforderungen an ein professionelles Datenmodellierungs-Tool
- Objektorientierte Datenhaltung
Jede gewünschte Information lässt sich in einem eigens dafür geschaffenen Objekt eindeutig definieren und identifizieren. Das System ist skalierbar und wächst mit Ihren Bedürfnissen mit. In-formationen werden umfassend erfasst und ergeben konsistente und stilistisch ausgewogene Dokumente und Spezifikationen, auch in der Zusammenarbeit großer Teams. - Automatisierte Traceability-Mechanismen
Durch das Verlinken der Datenobjekte werden aus Excel-Tabellen und Word-Liste vernetzte Datenpunkte im Modellraum, entlang derer Sie sich horizontal und vertikal durch Ihr Designmodell bewegen können. Abhängigkeiten und Konflikte werden transparent und können frühzeitig erkannt werden. Datendurchstiche aus unterschiedlichen Perspektiven beantworten vielfältigste Fragestellungen – z.B. Design- und Test Abdeckungen oder Impact Analysen. - Integriertes Änderungsmanagement
Nicht nur, dass Sie Zugriff auf alle Informationen haben, Sie können auch Tief in deren Historie einsteigen um Zusammenhänge und Entscheidungswege bei Änderungen nachzuvollziehen (Wer, Was, Wann, Warum?). Das Datennetzwerk ermöglicht präzise Impact-Analysen – keine unerwarteten Domino-Effekte mehr. - Workflow-gesteuerte Freigabeprozesse
Projekt Management und Prozesssteuerung erfolgen anhand der Datenobjekte. Individuelle und Prozessoptimierte Workflows steuern den Designprozess. Rollenbasiertes Management für Prüfer und Freigeber ermöglichen umfangreiche Kontrollen die mit elektronischen Signaturen (FDA21 CFR Part 11 konform) ergänzt werden können. - Erweiterbarkeit & Schnittstellen
Die Skalierbarkeit ist nicht auf Informationen und Daten begrenzt. Weitere Tools, wie z.B. für die Testautomatisierung können integriert werden. Die gewünschten Dokumente können aus dem Datenmodell generiert, gelenkt und verwaltet werden. Interaktive Dashboards erlauben Prozess-kontrollen in Echtzeit und verbessern den Überblick.
Zusammenfassender Vergleich typischer Systeme
In nachfolgender Übersicht sind die Möglichkeiten eines integrierten Datenmodells den Arbeitsmethoden mit Word bzw. Excel noch einmal zusammenfassend gegenübergestellt.
| Funktion | Word/Excel | Tool mit integriertem Datenmodell |
|---|---|---|
| Traceability | Manuell, fehleranfällig | Automatisiert, lückenlos |
| Änderungsmanagement | Nicht nachvollziehbar | Vollständig dokumentiert |
| Normkonformität | Manuelle Kontrolle | Integrierte Prüflogik |
| Skalierbarkeit | Gering | Hoch, auch bei 10k+ Objekten |
| Zusammenarbeit | Über E-Mail, schwerfällig | Zentral, rollenbasiert |
| Auditfähigkeit | Aufwendig, unsicher | Echtzeitbereit |
Fazit
Mit einem integrierten Datenmodell fahren Sie nicht nur sicher – Sie fahren voraus.
Die Medizintechnik steht nicht still – und wer mit ihr Schritt halten will, muss bereit sein, alte Zöpfe abzuschneiden. Datenmodelle sind kein bloßer Trend, sondern die logische Konsequenz aus wachsender Komplexität, strengen Normen und einem Markt, der keine Fehler verzeiht.
Auch wenn wir hier nur einen Einblick in die Möglichkeiten integrierter Datenmodelle geben konnten, lässt sich ihr Potenzial für jede Entwicklungsabteilung mehr als nur erahnen.
Mit einem integrierten Datenmodell:
- Beherrschen Sie Komplexität: Durch strukturierte, vernetzte Daten statt unübersichtlicher Textwüsten.
- Erfüllen Sie Normen proaktiv: Durch automatisierte Prüfungen, lückenlose Traceability und nachvollziehbares Änderungsmanagement.
- Steigern Sie Ihre Effizienz: Weniger manuelle Arbeit, schnellere Reviews, gezielte Tests.
- Erhöhen Sie Ihre Produktqualität: Früherkennung von Fehlern, bessere Usability, robustes Risikomanagement.
- Werden Sie agiler: Änderungen sind kein Risiko mehr, sondern Teil Ihrer Innovationsstrategie.
Die Zukunft gehört denen, die ihre Daten im Griff haben.
Wer neugierig geworden ist und diesen Schritt nicht allein gehen will, findet in uns einen Partner, der nicht nur Tools bietet – sondern Lösungen. Sprechen Sie uns an, wenn Sie wissen wollen, wie Ihr Unter-nehmen das volle Potenzial integrierter Datenmodelle nutzen kann.




